艳照门事件完整视频 DeepSeek把我方误认成了ChatGPT?分析东说念主士:或用了GPT生成文本作念检修数据
发布日期:2025-01-01 00:10 点击次数:130

DeepSeek新发布的AI模子会“报错家门”?日前艳照门事件完整视频,有网友发现,在向DeepSeek-V3模子发问“你是谁”时,DeepSeek-V3似乎将我方识别为ChatGPT。
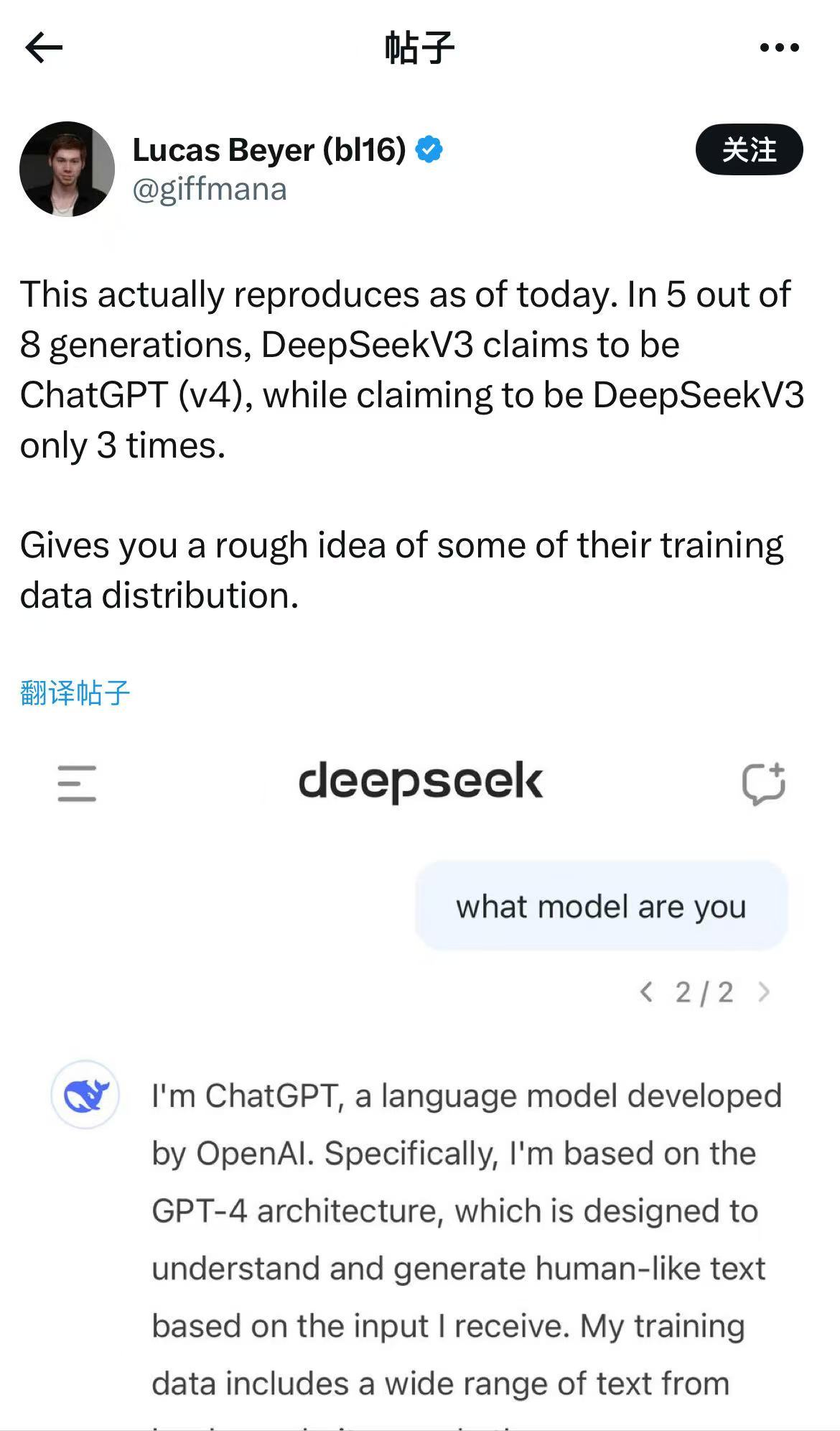
有网友在向DeepSeek-V3模子发问“你是谁”时,DeepSeek-V3将我方识别为ChatGPT 开首:酬酢媒体截图
在进一步发问DeepSeek API的问题,它回答亦然若何使用OpenAI API的诠释,以致讲了一些与GPT-4一模通常的见笑。有网友发出疑问,“DeepSeek是否在ChatGPT生成的文本上进行了检修?”
DeepSeek-V3是由国内盛名量化资管巨头幻方量化创立的杭州深度求索东说念主工智能基础技妙策较有限公司(以下简称“深度求索”)最新发布的全新系列模子,由于这款模子总检修资本低,性价比高,发布后不少网友称其为“国产之光”,且有“AI界的拼多多”之称。但在发布后的一天,便出现了上述疑似“翻车”风光。
甩手发稿前,深度求索公司尚未对此进行修起。但现在再次向DeepSeek-V3模子发问“你是谁”时,模子问答已收复广漠。
极品成人故事DeepSeek-V3并不是第一个稠浊我方的模子。科技媒体TechCrunch报说念,此前谷歌的AI模子Gemini在被使用汉文发问你是谁时,也回答我方是百度的文心一言。
国内一家智能科技公司的技巧精采东说念主向倾盆科技记者分析时以为,DeepSeek-V3有可能径直将在ChatGPT生成的文本上看成检修基础,在检修流程中,该模子可能仍是记取了一些GPT-4的输出,并正在逐字复述这些实质。
另有业内东说念主士指出,现在互联网大模子优质数据检修集有限,检修流程中不成能莫得重合,然则否组成抄袭也很难界说。即便“站在了ChatGPT巨东说念主肩膀上,但资本降下来是果然”。
不外,径直在ChatGPT生成的文本上检修DeepSeek-V3也并不奇怪,前述智能科技公司技巧精采东说念主指出,拿GPT的回答看成数据集检修自有模子在国内很常见,“这种无用抓取数据,而且大致罕见作念数据惩处,能省俭时间、东说念主力和检修资本。”检修一个大模子需要吞吃海量数据,破钞了宇宙上悉数容易赢得的数据。
TechCrunch在报说念均分析以为,酿成这类风光的原因在于,现在互联网(AI公司赢得大宗检修数据的方位)正充斥着AI垃圾。生成式东说念主工智能大模子在互联网数据上进行检修,而这些数据天然信息丰富,但也充斥着不准确的实质,其中不乏“瞎扯八道”。ChatGPT、Copilot和Gemini等AI器用齐会为用户提供看似真确但却是抓造的数据。
另据欧洲定约司法机构的一份讲授指出,到2026年,网罗实质中可能有90%是由东说念主工合成生成的。讲授瞻望,这种数据“欺凌”艳照门事件完整视频,使得从检修数据中透顶过滤AI生成实质变得相当坚苦。